
引言
本指南演示如何在AMD(原Xilinx)Kintex-7 FPGA上配置一个多吉比特收发器(MGT),并将其连接到Xillyp2p IP核。本示例中配置的是GTX;但对于7系列家族中的其他FPGA,几乎所有细节都相同。
这里展示的示例实现了IP核端口与API指南中所示的简化应用框图:
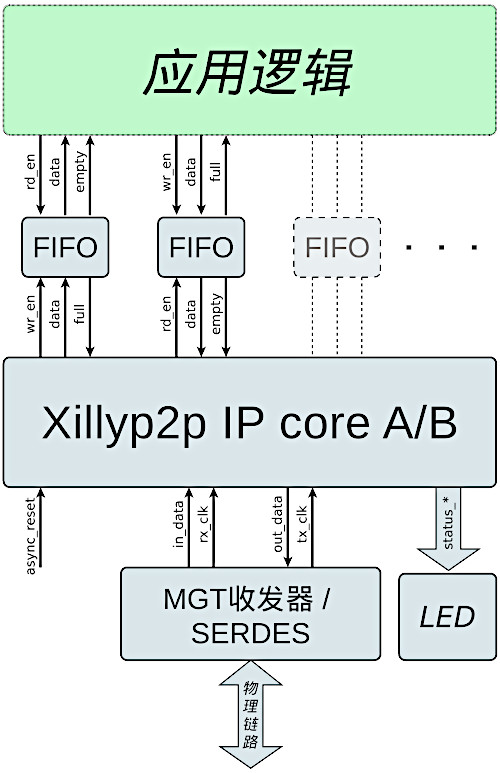
GTX与Xillyp2p之间的接口非常简单,如上图所示。然而,正确配置GTX并确定如何连接其端口可能颇具挑战。本指南给出了一个完整的设计示例,包括截图、Verilog代码和约束。
本示例以KC705板为目标,这是Kintex-7最常用的开发板。所展示的设计利用板上的SFP+接口,借助光收发模块和光纤与另一块板连接,数据速率为5 Gb/s(如上图所示)。
该设计可针对其他用途和接口进行修改。由于它使用了最简单的GTX配置(无编码),因此在出现连接问题时相对容易诊断。此外,Xillyp2p IP核提供了可连接到LED的诊断输出信号,如下所示。这些信号很有帮助,特别是其中一个LED会在物理链路上每出现一个比特错误时闪烁一次。
对于使用较新AMD FPGA(Ultrascale、Ultrascale+及更新型号)的用户,另有一份独立的指南,演示如何配置Ultrascale GTH(本示例使用的是GTX)。
配置收发器
以下通过截图和简要注释说明操作步骤。本示例使用Vivado 2025.1创建,但也兼容其他版本,可能仅有微小差异。
您也可以下载一个现成的XCI文件,该文件反映了此处所示的配置。
在Vivado中,打开IP Catalog并选择7 Series FPGAs Transceiver Wizard。按下图中的截图调整配置。请注意,可以通过Wizard内的子菜单对收发器进行更详细的配置,但并非必须:所有需要修改的地方都已在下图中标出。Wizard的“Start from scratch”默认配置在其他方面是合适的。
Wizard的初始窗口是“GT Selection”选项卡,应按如下方式配置:
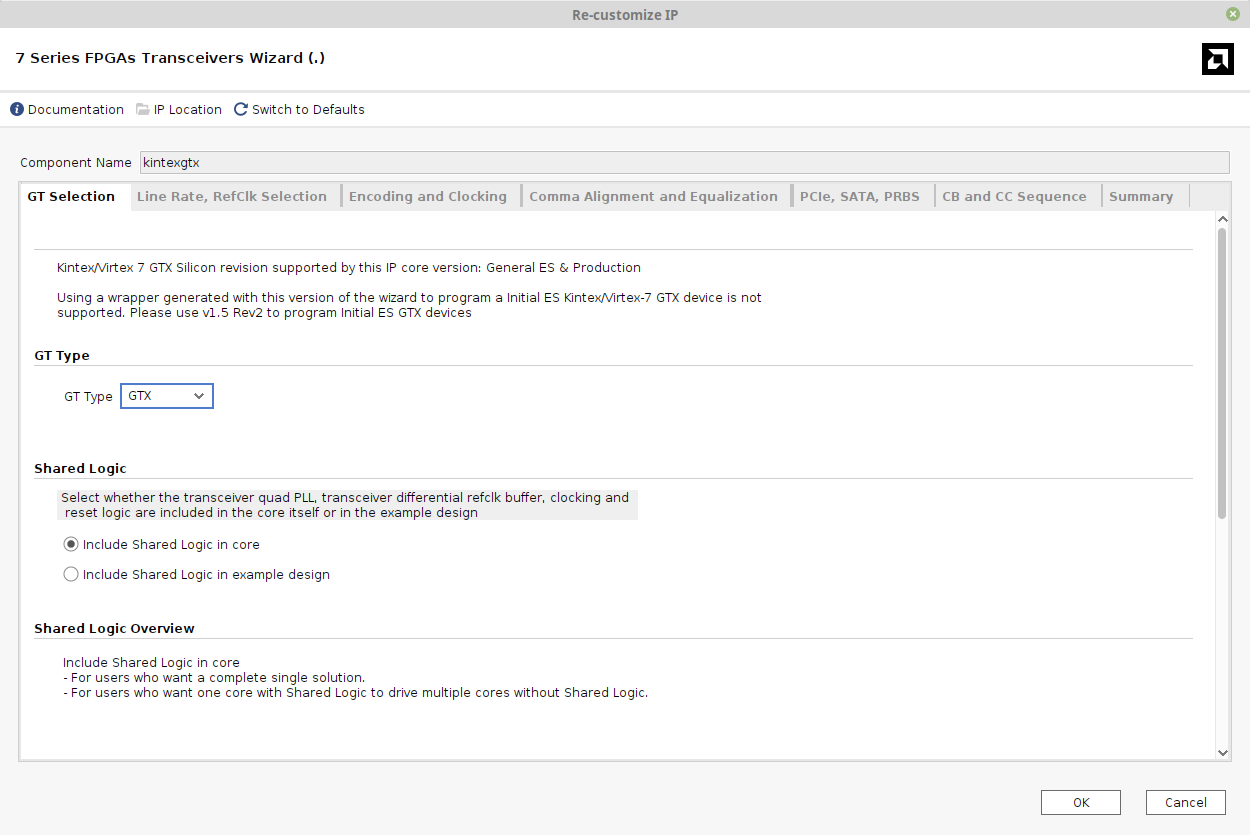
需要修改的地方:
- IP名称设为“kintexgtx”。这是下面Verilog例化中使用的名称。
- 选择“Include Shared Logic in core”。注意GT Type是“GTX”,这对Kintex-7是正确的。7系列中的其他FPGA使用不同的类型,例如Artix-7使用GTP。
下一个选项卡是“Line Rate, RefClk Selection”,如下所示:
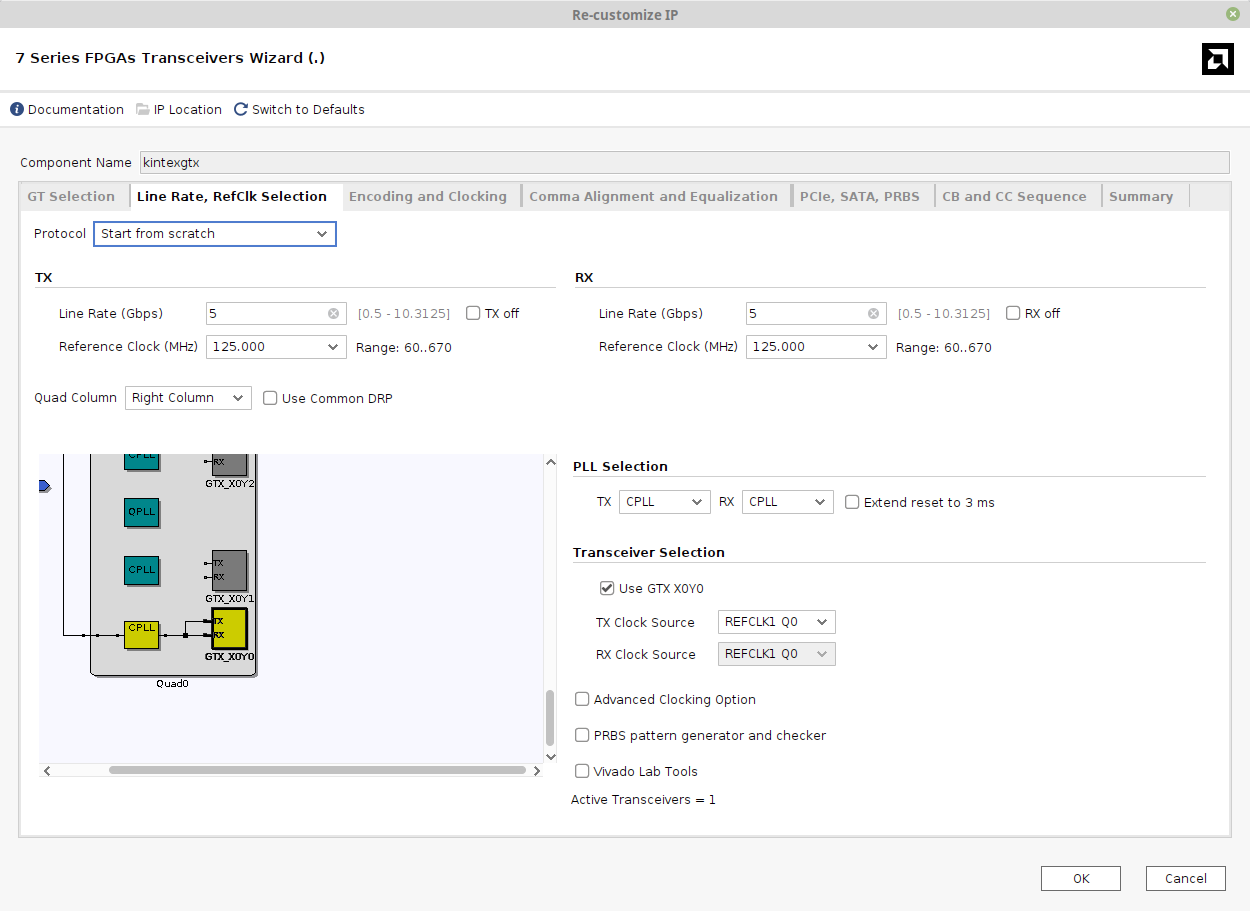
需要注意的地方:
- Line Rate在两个方向均设为5 Gb/s。您可以根据自己的设备选择不同的速率。
- 为简化起见,PLL类型选择CPLL。这是每个收发器独立的PLL,而Quad PLL则是在四个收发器间共享的,功能更丰富但使用也更复杂。
- “Actual Reference Clock”是外部参考时钟的频率。KC705板上,在引脚G8/G7处提供了一个低抖动125 MHz时钟源,因此使用该时钟。
“Transceiver Selection”部分允许选择使用FPGA的哪些GTX资源。这些设置会被项目XDC文件中的布局约束覆盖,因此该部分对最终结果没有影响。也可以删除XDC文件中的约束,而依赖这些设置。采用哪种方法是个人喜好问题;在本示例中,忽略Wizard的设置。
下一个选项卡是“Encoding and Clocking”:
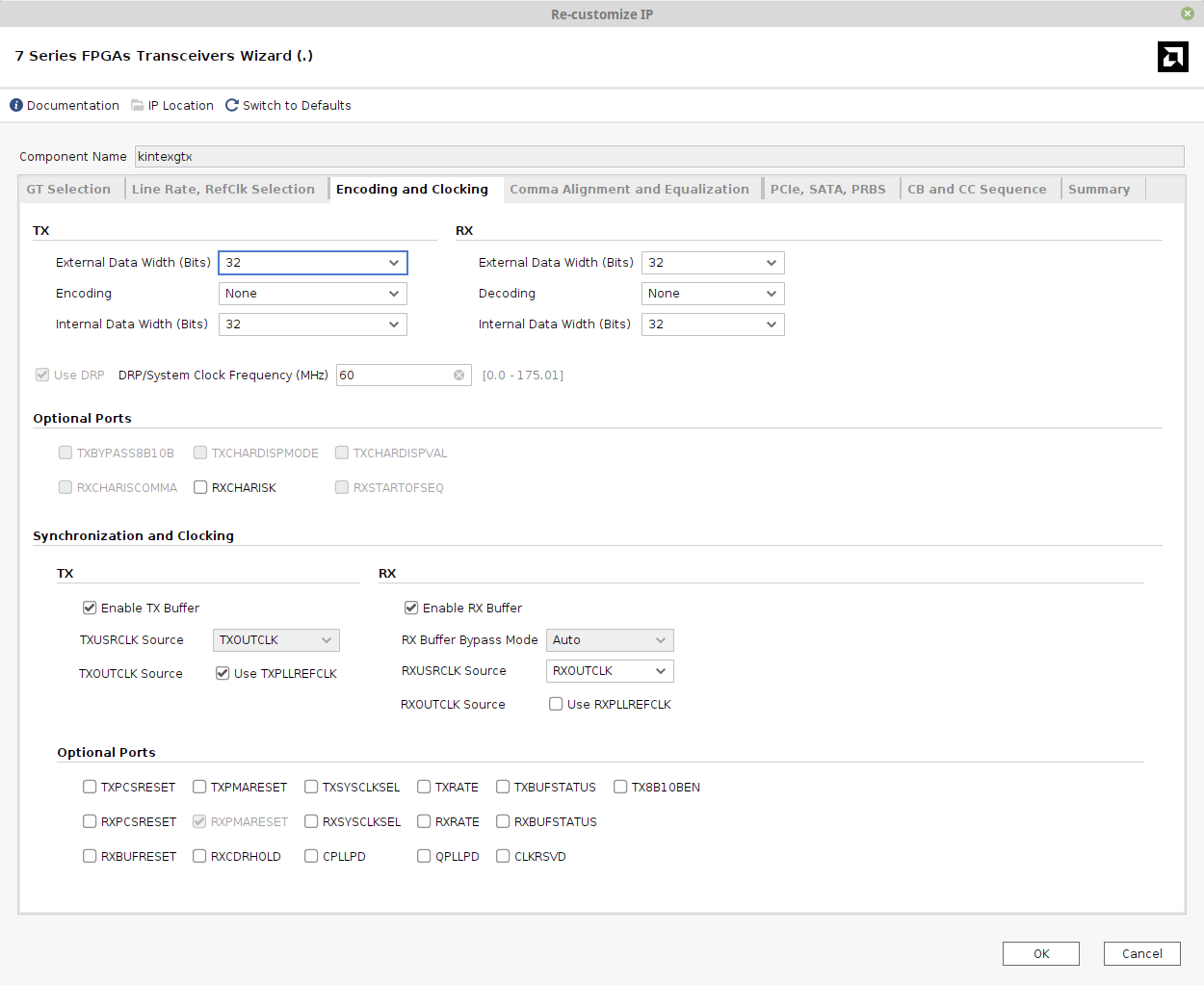
- “Encoding”保持默认设置Raw(无编码),因为Xillyp2p期望收发器表现为纯粹的SERDES,不对数据流做任何操作。
- 将TX和RX的External Data Width和Internal Data Width均设为32。External Data Width应与Xillyp2p IP核指定的并行字宽匹配。
- 将DRP/System Clock Frequency改为设计中自由运行时钟的频率。这是提供给收发器用于其内部管理任务的额外时钟。本示例中设为60 MHz。该时钟由MMCM基于板上的200 MHz时钟产生(见下文)。
- 将RXUSRCLK Source改为RXOUTCLK。
下一个选项卡是Comma Alignment and Equalization:
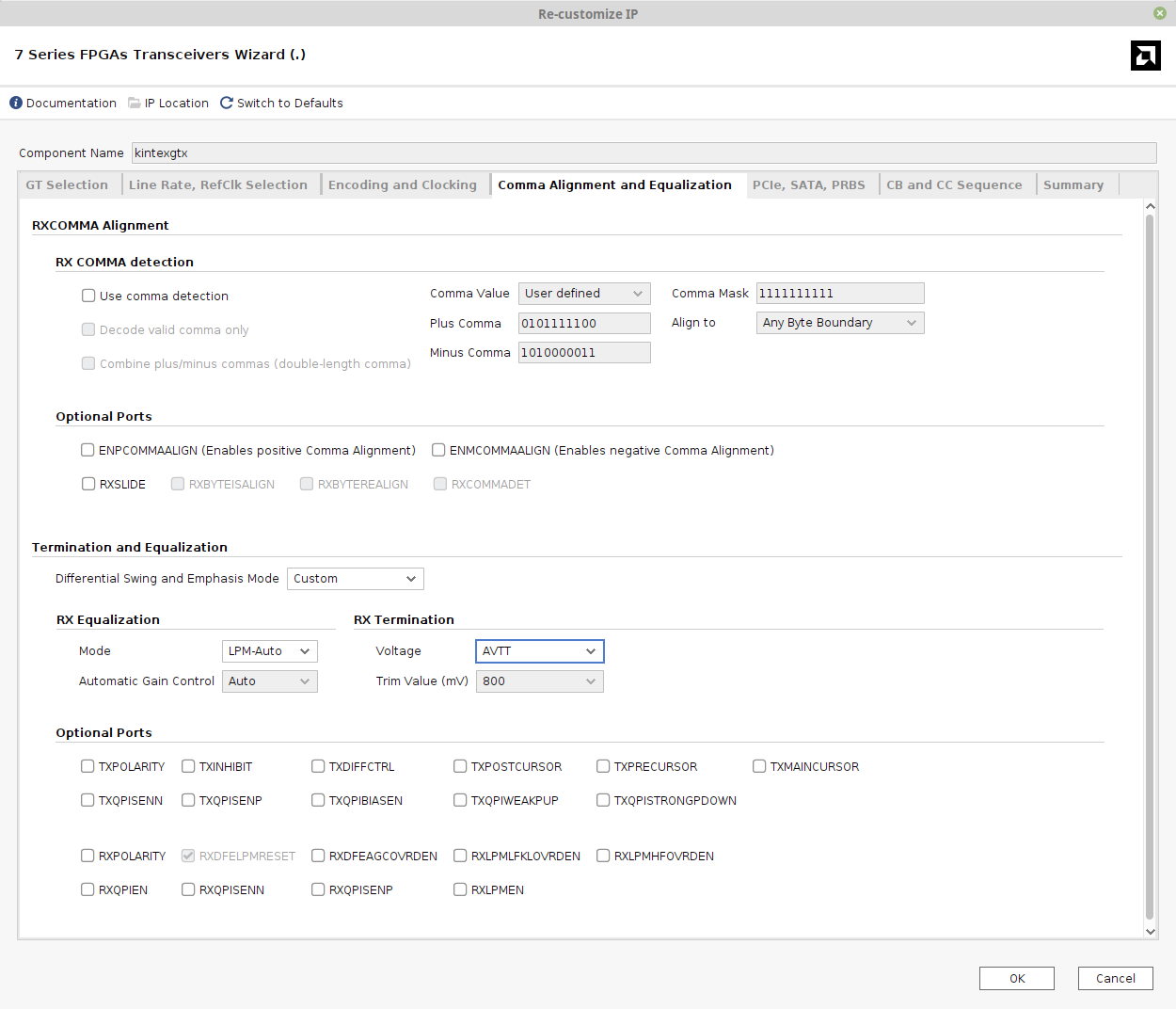
- 取消勾选“Use comma detection”。收发器的编码功能已关闭,Xillyp2p自行对齐输入数据流。
- 对于RX Equalization,选择LPM-Auto,以便进行下一步。
- 对于RX Termination,Voltage设为AVTT。这将设置施加到GTX电接收器输入端的偏置电压。如果您使用的不是带SFP+模块的光纤链路,可能需要不同的端接电压。此设置会显著影响链路质量。即使数据到达时每个并行字都有大量错误,调整电压有时也能使链路完全无差错。
下一个选项卡是“PCIe, SATA, PRBS”。这些功能均未启用,因此可以跳过此选项卡:
接下来的选项卡是“CB and CC Sequence”,也可以跳过:
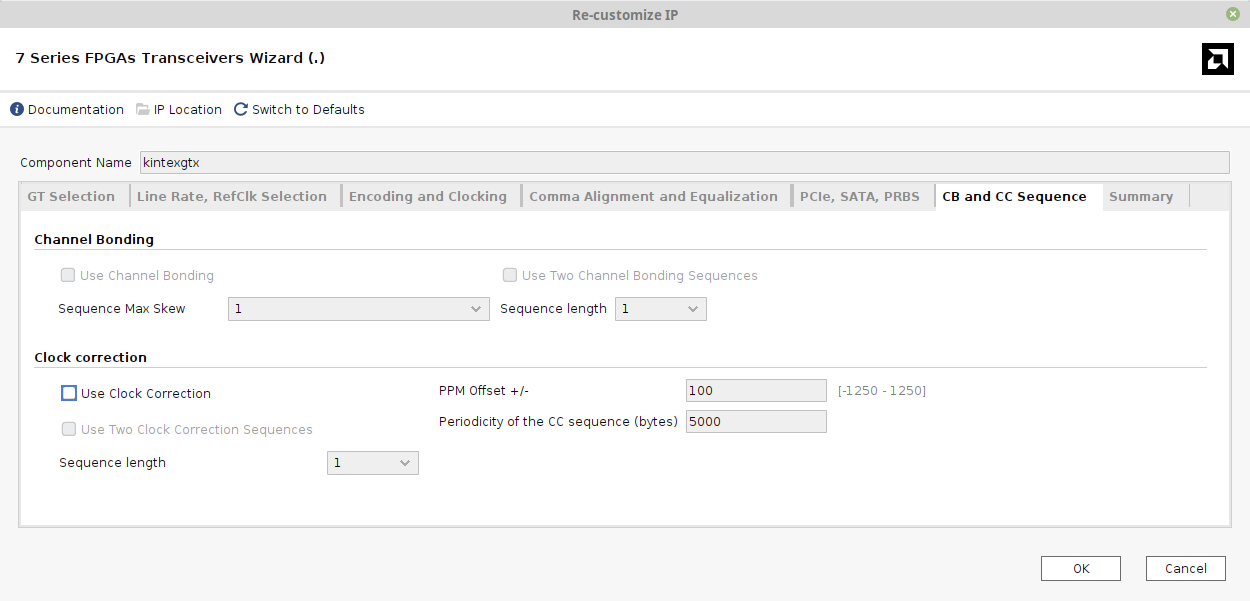
“Use Clock Correction”保持未勾选状态。Xillyp2p内部处理时钟校正,而由于编码被禁用,收发器无法执行此任务。
最后一个选项卡是摘要页面,如下所示:
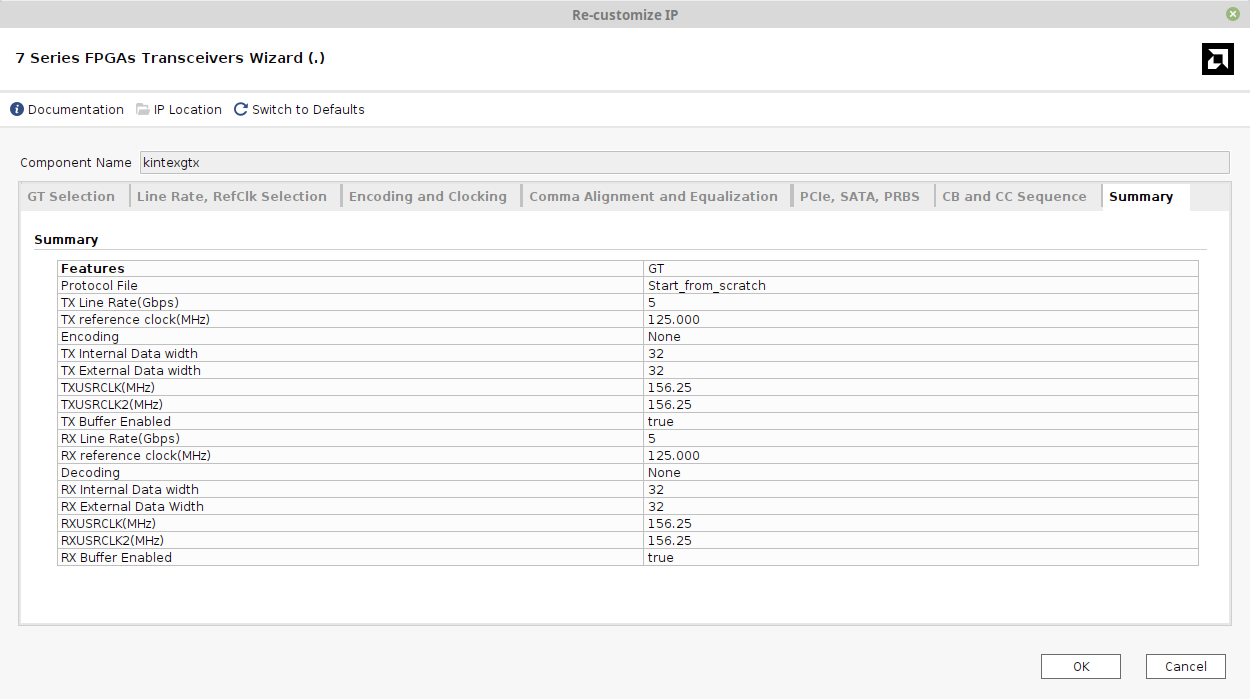
注意,与Ultrascale的示例不同,tx_clk(TXUSRCLK2)和rx_clk(RXUSRCLK2)的时钟频率与参考时钟不同:tx_clk和rx_clk运行在156.25 MHz(与Ultrascale相同),但参考时钟是125 MHz。
Xillyp2p IP核的配置仍然是正确的:其中指定的时钟频率对应tx_clk和rx_clk(156.25 MHz)。参考时钟仅与收发器的设置相关。
GTX的配置到此结束。接下来展示一个Verilog设计示例。
收发器的例化
顶层Verilog模块的开头如下:
module example
(
input gtx_refclk_n,
input gtx_refclk_p,
input gtx_rxn,
input gtx_rxp,
output gtx_txn,
output gtx_txp,
input clk_200_p,
input clk_200_n,
output sfp_tx_enable,
output [7:0] gpio_led
);
前六个端口属于GTX本身:参考时钟、接收和发送引脚。
clk_200_p/n端口是KC705板上200 MHz自由运行时钟的差分输入。sfp_tx_enable将在下面简要说明。
最后是八个LED输出。
收发器与Xillyp2p IP核之间的连接方式与Ultrascale的示例相同。主要区别在于收发器的例化。
在例化GTH本身之前,需要一个自由运行的时钟源。下面例化了一个MCMM,从KC705板提供的200 MHz时钟产生60 MHz时钟:
wire sysclk;
wire pll_locked;
syspll syspll_inst
(
.clk_in1_p(clk_200_p),
.clk_in1_n(clk_200_n),
.clk_out1(sysclk),
.locked(pll_locked)
);
使用Clocking Wizard创建syspll。相关的XCI文件可下载。
与Xillyp2p IP核接口需要以下线网:
wire rx_clk;
wire tx_clk;
wire async_reset;
wire [31:0] in_data;
wire [31:0] out_data;
assign async_reset = 0;
本示例中将async_reset接地。这有点随意,但设计仍然有效。在实际设计中,建议使用此异步复位在上电后立即复位逻辑。
接下来是一个小细节,但可能很重要:
assign sfp_tx_enable = 1; // Enable SFP+ transmitter
sfp_tx_enable输出端口通过一个MOSFET晶体管连接到光收发器的TX_DISABLE输入端,这会使其极性反转。默认情况下,板上的一个跳线使收发器的发送器保持使能。但如果该跳线缺失,收发器的发送器将被关闭。将此输出保持为高电平时,TX_DISABLE被强制为低电平,确保光收发器正常工作。
现在例化收发器:
kintexgtx kintexgtx_i
(
.soft_reset_tx_in(!pll_locked), // Input is asynchronous
.soft_reset_rx_in(!pll_locked), // Input is asynchronous
.dont_reset_on_data_error_in(1'b1),
.q0_clk1_gtrefclk_pad_n_in(gtx_refclk_n),
.q0_clk1_gtrefclk_pad_p_in(gtx_refclk_p),
.gt0_tx_fsm_reset_done_out(),
.gt0_rx_fsm_reset_done_out(),
.gt0_data_valid_in(1'b1),
.sysclk_in(sysclk),
.gt0_txusrclk_out(),
.gt0_txusrclk2_out(tx_clk),
.gt0_rxusrclk_out(),
.gt0_rxusrclk2_out(rx_clk),
.gt0_rxdata_out (in_data),
.gt0_txdata_in (out_data),
.gt0_gtxrxp_in (gtx_rxp),
.gt0_gtxrxn_in (gtx_rxn),
.gt0_gtxtxn_out (gtx_txn),
.gt0_gtxtxp_out (gtx_txp),
// Unused ports:
.gt0_cpllfbclklost_out (),
.gt0_cplllock_out (),
.gt0_cpllreset_in (1'b0),
.gt0_drpaddr_in (9'd0),
.gt0_drpdi_in (16'd0),
.gt0_drpdo_out (),
.gt0_drpen_in (1'b0),
.gt0_drprdy_out (),
.gt0_drpwe_in (1'b0),
.gt0_dmonitorout_out (),
.gt0_eyescanreset_in (1'b0),
.gt0_rxuserrdy_in (1'b0),
.gt0_eyescandataerror_out (),
.gt0_eyescantrigger_in (1'b0),
.gt0_rxdfelpmreset_in (1'b0),
.gt0_rxmonitorout_out (),
.gt0_rxmonitorsel_in (2'b00),
.gt0_gtrxreset_in (1'b0),
.gt0_rxpmareset_in (1'b0),
.gt0_rxresetdone_out (),
.gt0_gttxreset_in (1'b0),
.gt0_txuserrdy_in (1'b0),
.gt0_txoutclkfabric_out (),
.gt0_txoutclkpcs_out (),
.gt0_txresetdone_out (),
.gt0_qplloutclk_out(),
.gt0_qplloutrefclk_out()
);
收发器直接连接到物理引脚gth_rxp、gth_rxn、gth_txp和gth_txn。与GTH示例不同,参考时钟的缓冲器包含在收发器模块内,因此gtx_refclk_p和gtx_refclk_n也直接连接到收发器模块。
60 MHz的自由运行时钟sysclk连接到sysclk_in。如上所述,该时钟用于收发器的控制逻辑,包括初始化。由于MMCM需要短暂时间才能锁定到其200 MHz参考时钟,因此使用取反后的pll_locked信号来复位收发器。这确保初始化仅在sysclk稳定后开始。
注意tx_clk和rx_clk是收发器的输出。换句话说,收发器通过gt0_txusrclk2_out和gt0_rxusrclk2_out端口提供这两个时钟。与in_data和out_data一起,这些就是收发器与Xillyp2p IP核之间的所有连接,如下所示。
Xillyp2p IP核的例化
在本示例中,使用在IP Core Factory生成的一个IP核中的Core A。Core B应使用在物理链路的另一端(除非该核是对称的,这一主题在IP Core Factory指南的末尾有说明)。
IP核的配置如Web应用程序中的截图所示:
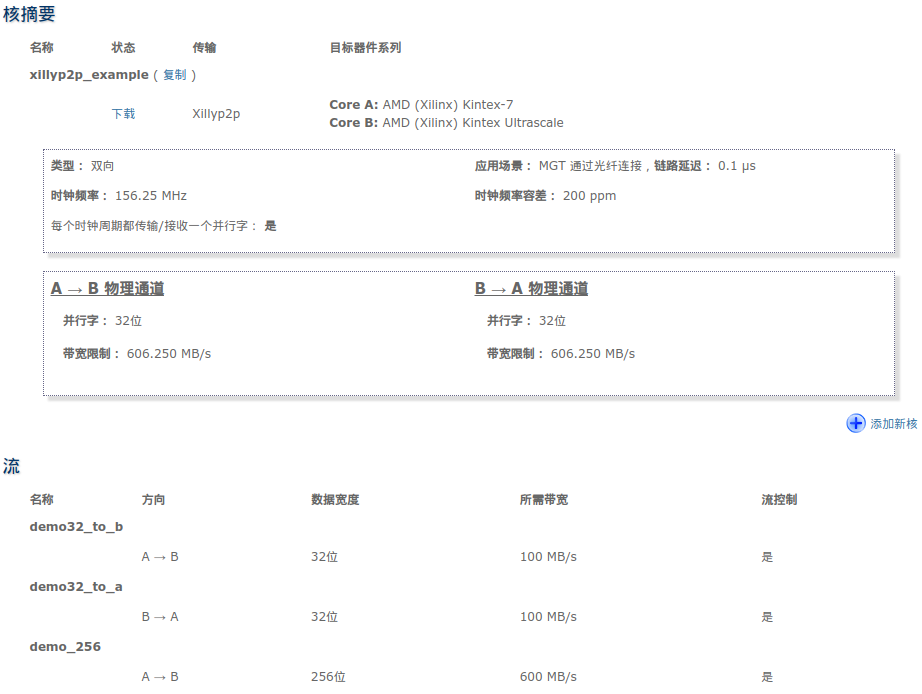
IP核的通用参数与GTX匹配:32位并行字宽,时钟频率156.25 MHz。注意,这是rx_clk和tx_clk的频率,而不是参考时钟的频率。例如,如果更改了GTX的Line Rate(而不改变参考时钟和并行字宽),rx_clk和tx_clk的频率将相应改变。在这种情况下,应在IP Core Factory中指定更新后的频率。
为该IP核定义了三个stream:demo32_to_b、demo32_to_a和demo_256。可以根据应用需要配置不同数量、不同名称和属性的stream。
在例化IP核之前,还需要一些额外的线网。以下代码段直接从IP核的例化模板中复制而来:
wire status_link_down;
wire status_initializing;
wire status_link_partner_mismatch;
wire status_bit_error;
wire status_rev_polarity;
wire [31:0] status_debug;
wire [2:0] error_test_rate;
// Wires related to data stream "demo32_to_a"
wire user_rx_demo32_to_a_wr_en;
wire [31:0] user_rx_demo32_to_a_wr_data;
wire user_rx_demo32_to_a_full;
wire user_rx_demo32_to_a_eop;
// Wires related to data stream "demo32_to_b"
wire user_tx_demo32_to_b_rd_en;
wire [31:0] user_tx_demo32_to_b_rd_data;
wire user_tx_demo32_to_b_empty;
wire user_tx_demo32_to_b_eop;
// Wires related to data stream "demo_256"
wire user_tx_demo_256_rd_en;
wire [255:0] user_tx_demo_256_rd_data;
wire user_tx_demo_256_empty;
wire user_tx_demo_256_eop;
现在进行例化本身。这部分也复制自Core A的例化模板:
xillyp2p_core_a xillyp2p_core_a_ins (
// Ports related to data stream "demo32_to_a"
// Inbound data stream:
.user_rx_demo32_to_a_wr_en(user_rx_demo32_to_a_wr_en),
.user_rx_demo32_to_a_wr_data(user_rx_demo32_to_a_wr_data),
.user_rx_demo32_to_a_full(user_rx_demo32_to_a_full),
.user_rx_demo32_to_a_eop(user_rx_demo32_to_a_eop),
// Ports related to data stream "demo32_to_b"
// Outbound data stream:
.user_tx_demo32_to_b_rd_en(user_tx_demo32_to_b_rd_en),
.user_tx_demo32_to_b_rd_data(user_tx_demo32_to_b_rd_data),
.user_tx_demo32_to_b_empty(user_tx_demo32_to_b_empty),
.user_tx_demo32_to_b_eop(user_tx_demo32_to_b_eop),
// Ports related to data stream "demo_256"
// Outbound data stream:
.user_tx_demo_256_rd_en(user_tx_demo_256_rd_en),
.user_tx_demo_256_rd_data(user_tx_demo_256_rd_data),
.user_tx_demo_256_empty(user_tx_demo_256_empty),
.user_tx_demo_256_eop(user_tx_demo_256_eop),
// General signals
.rx_clk(rx_clk),
.tx_clk(tx_clk),
.async_reset(async_reset),
.in_data(in_data),
.out_data(out_data),
.status_link_down(status_link_down),
.status_initializing(status_initializing),
.status_link_partner_mismatch(status_link_partner_mismatch),
.status_bit_error(status_bit_error),
.status_rev_polarity(status_rev_polarity),
.status_debug(status_debug),
.error_test_rate(error_test_rate)
);
// error_test_rate should always be zero unless you want to the test
// what happens when there are errors on the physical data link.
assign error_test_rate = 3'd0;
如前所述,IP核通过四根线网与GTX连接:rx_clk、tx_clk、in_data和out_data。其余连接与应用逻辑相关,下面将讨论。
与应用逻辑交换数据
使用过Xillybus的PCIe或XillyUSB IP核的用户会对这部分感到非常熟悉。
首先,回顾一下,本示例围绕Core A展开,而Core B(通常)应使用在物理链路另一端的FPGA上。
名为“demo32_to_a”的应用数据stream允许另一侧(带有Core B)的FPGA向带有Core A的FPGA发送数据。
访问这些数据的主流方法是通过FIFO。例如,fifo_32是一个在Vivado项目中定义的标准双时钟FIFO,数据字宽32位,例化如下:
fifo_32 data_in_fifo
(
.rst(async_reset),
.wr_clk(tx_clk),
.rd_clk(<连接到应用逻辑>),
.din(user_rx_demo32_to_a_wr_data),
.wr_en(user_rx_demo32_to_a_wr_en),
.full(user_rx_demo32_to_a_full),
.rd_en(<连接到应用逻辑>),
.dout(<连接到应用逻辑>),
.empty(<连接到应用逻辑>)
);
名为user_rx_demo32_to_a_*的三根线网连接到Xillyp2p IP核。IP核使用这些信号将从Core B到达的数据写入FIFO。
注意FIFO的“full”端口也已连接。Xillyp2p IP核会尊重该信号,并通过其流控机制避免溢出。该机制是可选的,但推荐使用(注意在IP核配置截图中,所有三个stream的“Flow control”列都显示为“Yes”)。
FIFO的其余端口连接到应用逻辑,由应用逻辑按需读取数据。应用逻辑不需要以特定速率读取数据;唯一的要求是避免在FIFO为空时尝试读取。
还要注意,FIFO的wr_clk端口连接到tx_clk,尽管它用于接收数据。所有与应用逻辑的交互都基于tx_clk。不要被其他信号名称中的“rx”前缀搞混——rx_clk仅与收发器相关,并且仅与in_data一起使用。
对于相反方向的数据流,“demo32_to_b”允许Core A向另一侧(带有Core B)的FPGA发送数据。用于此目的的FIFO例化如下:
fifo_32 data_out_fifo
(
.rst(async_reset),
.wr_clk(<连接到应用逻辑>),
.rd_clk(tx_clk),
.din(<连接到应用逻辑>),
.wr_en(<连接到应用逻辑>),
.full(<连接到应用逻辑>),
.rd_en(user_tx_demo32_to_b_rd_en),
.dout(user_tx_demo32_to_b_rd_data),
.empty(user_tx_demo32_to_b_empty)
);
assign user_tx_demo32_to_b_eop = 0;
名为user_tx_demo32_to_b_*的三根线网连接到Xillyp2p IP核。IP核使用这些信号在FIFO变为非空时立即从中读取数据。
FIFO的其他端口连接到应用逻辑,由应用逻辑以常规方式写入FIFO。应用逻辑向FIFO写入多少数据没有要求,也不需要特殊操作就能使数据到达另一端。唯一明显的要求是避免在FIFO已满时写入。
由于该stream启用了流控,只有当对端的FIFO未满时,才会从本端FIFO读取数据。因此,Core B侧的应用逻辑实际上控制了端到端的数据流:如果对侧(带有Core B)的应用逻辑从其FIFO读取数据的速度慢于本侧(Core A)向FIFO写入数据的速度,本侧的FIFO最终将变满,从而迫使应用逻辑停止写入。换句话说,这种安排等效于一个写端口在一个FPGA上、读端口在另一个FPGA上的单一FIFO。
另请注意,本设计中未使用user_rx_demo32_to_a_eop,而user_tx_demo32_to_b_eop被接地。这两个端口与在数据字旁边发送包结束标志(EOP)的能力有关。当需要通过stream发送数据段或数据包时,此功能很有用。有关EOP的更多信息,请参阅Xillyp2p端口与API指南。
关于数据交换的几点说明
出于测试目的,将来自Core B的数据环回至Core B可能很有用。换句话说,将从“demo32_to_a”接收到的数据直接路由到“demo32_to_b”。这可以通过例化一个FIFO而不是两个来实现,如下所示:
fifo_32 loopbackfifo
(
.rst(async_reset),
.wr_clk(tx_clk),
.rd_clk(tx_clk),
.din(user_rx_demo32_to_a_wr_data),
.wr_en(user_rx_demo32_to_a_wr_en),
.full(user_rx_demo32_to_a_full),
.rd_en(user_tx_demo32_to_b_rd_en),
.dout(user_tx_demo32_to_b_rd_data),
.empty(user_tx_demo32_to_b_empty)
);
assign user_tx_demo32_to_b_eop = 0;
再次注意,FIFO的两侧都使用tx_clk。
与“demo_256”的接口以相同方式处理,使用一个256位数据字宽的FIFO。注意,该stream使用256位宽的数据字,远大于物理链路的32位并行字。同时,该stream的最大理论数据速率为256 * 156.25 MHz / 8 = 5000 MB/s,远高于物理链路约606 MB/s的容量。
然而,如果应用的自然数据格式由256位字组成,那么使用256位宽的stream是合适的,尽管它不提供带宽优势。这种选择确保每个字以正确的格式和正确的对齐方式在接收端传递。
LED与诊断信号
KC705板上有8个GPIO LED。Xillyp2p IP核有几个可以连接到LED的输出,用于指示链路状态,详细信息请参阅这篇指南。
推荐的设置如下:
reg [26:0] txclk_cnt, sysclk_cnt;
always @(posedge sysclk)
sysclk_cnt <= sysclk_cnt + 1;
always @(posedge tx_clk)
txclk_cnt <= txclk_cnt + 1;
assign gpio_led[1:0] = { txclk_cnt[26], sysclk_cnt[26] };
ledhelper ledhelper_ins[5:0]
(
.clk(tx_clk),
.in( {
status_link_down,
status_link_partner_mismatch,
status_initializing,
status_bit_error,
status_debug[2],
status_debug[0] } ),
.led(gpio_led[7:2])
);
对于不太熟悉Verilog的用户,ledhelper被实例化了六次,每次独立对应“in”输入的一位及其相应的“led”输出。
从上面可以看出,GPIO LED 0和1是简单的心跳信号,通过闪烁指示sysclk和tx_clk处于活动状态。
其余六个LED显示Xillyp2p IP核的六个状态信号的状态。ledhelper模块确保LED点亮或熄灭的时间足够长,使人眼能够感知到仅持续一个时钟周期的短暂事件。例如,当物理链路上检测到错误时,status_bit_error在一个时钟周期内为高。如果没有ledhelper,这样短暂的事件将是不可见的。
ledhelper模块定义如下:
module ledhelper(
input clk,
input in,
output reg led
);
// 22 bits = 4194304 counts, ~26.8 ms at 156.25 MHz clock
reg [21:0] count;
always @(posedge clk)
if (count != 0)
count <= count - 1;
else if (in != led)
begin
led <= in;
count <= ~0;
end
endmodule
该模块在每次变化后的222个时钟周期内冻结“led”输出。因此,如果输入在一个时钟周期内为高,LED将保持点亮约26.8毫秒,这足够长,使人眼能够感知到。此外,如果输入快速变化,LED会剧烈闪烁,人眼会将其正确解读为高活动性。
当有8个LED可用时,这种方法很合适。如果可用的LED较少,status_bit_error通常是最有用的指示器,其次是status_link_partner_mismatch、status_link_down和status_debug[2]。同时建议至少使用一个心跳LED。
XDC约束
为完整起见,展示并解释XDC文件中的约束。请记住,开发板是KC705。
首先,直接与收发器相关的约束:
create_clock -name refclk -period 8 [get_ports gtx_refclk_n]
set_property PACKAGE_PIN G8 [get_ports gtx_refclk_p]
set_property PACKAGE_PIN G7 [get_ports gtx_refclk_n]
set_property LOC GTXE2_CHANNEL_X0Y10 \
[get_cells -hierarchical -filter {name =~ */gtxe2_i}]
参考时钟的频率声明为8 ns,即125 MHz,与上文一致。请注意,与Ultrascale的示例不同,rx_clk和tx_clk具有不同的时钟频率(156.25 MHz)。
然后明确放置参考时钟的引脚,覆盖Wizard中的定义。
之后,为收发器显式选择GTX,再次覆盖Wizard中的选择。
接下来是自由运行时钟的约束:
set_property PACKAGE_PIN AD12 [get_ports clk_200_p] set_property PACKAGE_PIN AD11 [get_ports clk_200_n] set_property IOSTANDARD LVDS [get_ports clk_200_p] set_property IOSTANDARD LVDS [get_ports clk_200_n]
该自由运行时钟没有时序约束,因为Clocking Wizard会处理这一点。
由于两个时钟都已定义和约束,需要告诉Vivado逻辑设计将sysclk、rx_clk和tx_clk视为不相关的时钟,因此跨越这些时钟域的所有路径都是伪路径:
set_clock_groups -asynchronous \
-group [get_clocks -of_objects \
[get_pins kintexgtx_i/sysclk_in]] \
-group [get_clocks -of_objects \
[get_pins kintexgtx_i/gt0_txusrclk2_out]] \
-group [get_clocks -of_objects \
[get_pins kintexgtx_i/gt0_rxusrclk2_out]]
如果没有这一条,设计将无法满足时序约束。
最后是GPIO LED和sfp_tx_enable(简单部分):
set_property -dict {PACKAGE_PIN AB8 IOSTANDARD LVCMOS15} \
[get_ports {gpio_led[0]}]
set_property -dict {PACKAGE_PIN AA8 IOSTANDARD LVCMOS15} \
[get_ports {gpio_led[1]}]
set_property -dict {PACKAGE_PIN AC9 IOSTANDARD LVCMOS15} \
[get_ports {gpio_led[2]}]
set_property -dict {PACKAGE_PIN AB9 IOSTANDARD LVCMOS15} \
[get_ports {gpio_led[3]}]
set_property -dict {PACKAGE_PIN AE26 IOSTANDARD LVCMOS18} \
[get_ports {gpio_led[4]}];
set_property -dict {PACKAGE_PIN G19 IOSTANDARD LVCMOS18} \
[get_ports {gpio_led[5]}];
set_property -dict {PACKAGE_PIN E18 IOSTANDARD LVCMOS18} \
[get_ports {gpio_led[6]}];
set_property -dict {PACKAGE_PIN F16 IOSTANDARD LVCMOS18} \
[get_ports {gpio_led[7]}];
set_false_path -to [get_ports "gpio_led[*]"]
set_property -dict {PACKAGE_PIN Y20 IOSTANDARD LVCMOS18} \
[get_ports sfp_tx_enable];
注意,一半的LED使用LVCMOS15 I/O标准,另一半使用LVCMOS18。这是KC705板的一个小特性,Vivado会给出一个警告,应忽略该警告。
结论
本指南提供了一个完整的示例,演示了如何在AMD(原Xilinx)Kintex-7 FPGA上配置多吉比特收发器(GTX)并将其连接到Xillyp2p IP核。从Vivado中的Transceiver Wizard配置开始,经过例化时钟、FIFO和应用逻辑,到连接诊断LED和定义XDC约束,每一步都进行了详细解释。
该示例既可作为实际参考,也可作为学习使用7系列FPGA收发器和Xillyp2p IP核的工具。
请回顾上文,关于为较新AMD FPGA(Ultrascale、Ultrascale+及更新型号)配置收发器的示例,请参阅另一份指南。